Random Oversampling and Undersampling for Imbalanced Classification
Imbalanced datasets are those where there is a severe skew in the class distribution, such as 1:10 or 1:100examples in the minority class to the majority class
In this article we will have a look at Random Oversampling and Random Undersampling .
Let’s get started
First let’s load our data and Import some python libraries that we will need to load data.
#Import Libraries:
import numpy as np
import pandas as pd#Read data
df =pd.read_csv('classification.csv')
df.head()

Now that we have load the data let’s split our data into X and y
#Split our data into features(X) and labels(y)
X=df.drop(‘Activity’,axis=1)
y=df['Activity']Distribution Class
y.value_counts()
we can see that our target(labels) data it’s unbalanced let us show this using pie chart
#let's show this with pie chart first approachy.value_counts().plot.pie(autopct='%.2f')

In our approach dealing with Imbalanced dataset we will be using the following methods:
- Random Oversampling
not majority = resample all classes but the majority class
- Random Undersampling
not minority = resample all classes but the minority class
Random Undersampling
from imblearn.under_sampling import RandomUnderSamplerrus = RandomUnderSampler(sampling_strategy=1) # Numerical value# rus = RandomUnderSampler(sampling_strategy="not minority") # StringX_res, y_res = rus.fit_resample(X, y)ax = y_res.value_counts().plot.pie(autopct='%.2f')_ = ax.set_title("Under-sampling")

#class distribution
y_res.value_counts()
We can see now we have our data balanced using Random Under Sampling
Random Oversampling
from imblearn.over_sampling import RandomOverSampler#ros = RandomOverSampler(sampling_strategy=1) # Floatros = RandomOverSampler(sampling_strategy="not majority") # StringX_res, y_res = ros.fit_resample(X, y)ax = y_res.value_counts().plot.pie(autopct='%.2f')_ = ax.set_title("Over-sampling")
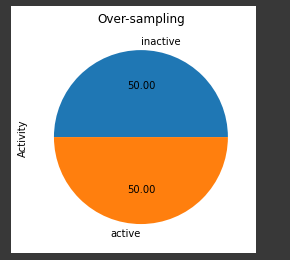
y_res.value_counts()
There we go we now have our data balanced with Random OverSampling
Let’s create some Decision Tree Model with RandomnderSampling to see how the model performs.
from numpy import meanfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.tree import DecisionTreeClassifierfrom imblearn.pipeline import Pipelinefrom imblearn.over_sampling import RandomOverSampler# define pipelinesteps = [('under',RandomUnderSampler()), ('model', DecisionTreeClassifier())]pipeline = Pipeline(steps=steps)# evaluate pipelinecv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)scores = cross_val_score(pipeline, X, y, scoring='f1_micro', cv=cv, n_jobs=-1)score = mean(scores)print('F1 Score: %.3f' % score)F1 Score: 0.841
Lets create some Decision Tree Model with Random OverSampling
from numpy import meanfrom sklearn.model_selection import cross_val_scorefrom sklearn.model_selection import RepeatedStratifiedKFoldfrom sklearn.tree import DecisionTreeClassifierfrom imblearn.pipeline import Pipelinefrom imblearn.over_sampling import RandomOverSampler# define pipelinesteps = [('over', RandomOverSampler()), ('model', DecisionTreeClassifier())]pipeline = Pipeline(steps=steps)# evaluate pipelinecv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)scores = cross_val_score(pipeline, X, y, scoring='f1_micro', cv=cv, n_jobs=-1)score = mean(scores)print('F1 Score: %.3f' % score)F1 Score: 0.986
Conclusion
As you may have guessed this methods has some advantages and their disadvantages you may want to check other methods to see which ones do great job.
Thank you for reading.
Please let me know if you have any feedback.
